Why most SaaS localization workflows can't keep up with continuous deployment
A SaaS client came to us with a problem that took me a while to fully understand. They were shipping product faster than their localization workflow could move. Three vendors, 25 languages, 5-day turnaround, and roughly 1 in 6 sprints missing translations at release. Here is what we found when we rebuilt their pipeline.
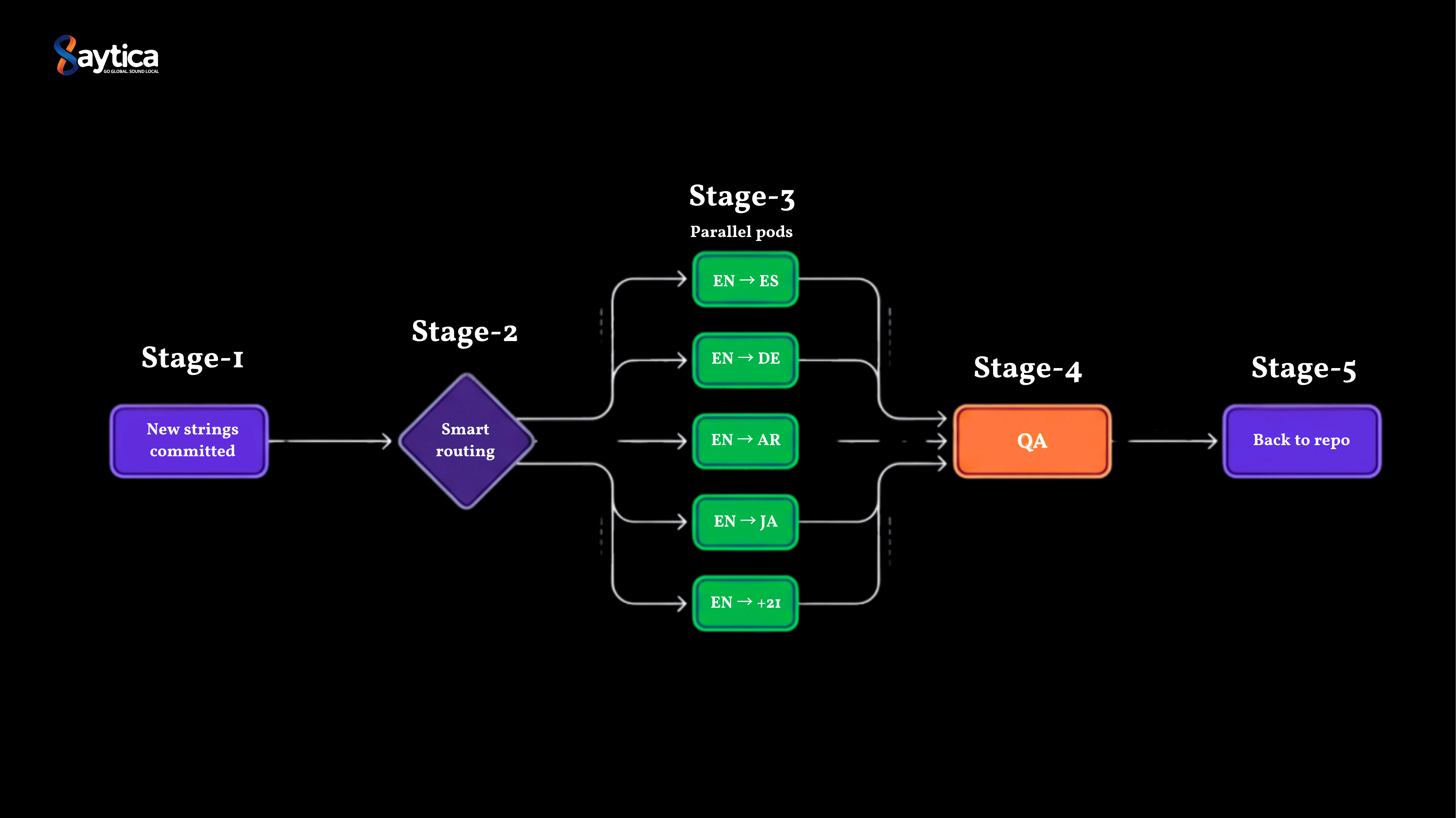
The first time I saw their workflow diagram, I thought there had to be more to it. There wasn't.
A developer would commit a new string. The string would sit in their TMS until the Head of Globalization's team noticed and exported a batch. The batch would get emailed to one of three regional vendors based on language. The vendor would translate, review internally, email it back. The Head of Globalization's team would import it, run QA, push it to the right branch. Five days, on a good week.
This is not an unusual setup. It's roughly how 70% of mid-market SaaS companies handle localization today, in my experience. It works, in the sense that strings eventually get translated. But it's built for a release cadence that doesn't exist anymore.
I want to write about this project because I think the shift from "translation as a deliverable" to "translation as a pipeline" is one of the most under-discussed changes in our industry, and a lot of localization buyers are stuck between the two models without realizing it.
What "continuous" actually means
The word "continuous" gets thrown around a lot in localization marketing. It usually means "we have an API." Having an API is necessary but not sufficient. A pipeline is continuous when human intervention is the exception, not the default.
In the client's previous workflow, every step required a human to move content between systems. Developer commits string, PM notices, PM exports, PM emails vendor, vendor receives, vendor assigns, translator translates, translator returns, vendor sends back, PM imports, QA runs. Ten handoffs. Each handoff is a place where time gets lost and errors get introduced.
A continuous workflow eliminates handoffs by integrating systems directly. Developer commits string. The TMS webhook fires. Our routing layer picks it up, assigns it to the right language pod based on tags and priority. Translator works in the TMS interface. Reviewer approves. Automated QA runs. String flows back into the right branch. No emails. No exports. No manual imports.
The translator and reviewer are still humans. The orchestration is not.
The three things that broke when we started measuring
When we instrumented the old workflow to understand where time was actually going, three things came out.
First, the wait between handoffs was longer than the actual translation work. A typical string was being worked on for maybe 30 minutes total. It was sitting in queues for the rest of the five days. Linguists weren't slow. The system was.
Second, the three vendors had developed conflicting terminology over time. The client's UI used three different translations of the same English term across different features, depending on which vendor had handled which screen. Their TM showed it (62% of high-frequency terms had inconsistent translations across vendor TMs) but nobody had been reconciling it.
Third, the strings that broke production weren't usually bad translations. They were strings that were technically correct but exceeded UI character limits, or that broke ICU MessageFormat placeholders, or that didn't handle plural rules correctly for languages with complex plural systems (Polish has four plural forms, Arabic has six, and most translation workflows don't catch when these are wrong).
The translation industry talks a lot about quality. The actual quality risks in SaaS localization are usually engineering risks, not linguistic ones.
What the rebuild actually looked like
I'll skip the long version. Three things mattered most.
We integrated directly with their TMS through API and webhooks, so new content routed to the right language pod automatically. The routing logic considered content type (UI string, help article, email template), priority tag (P0 hotfix versus standard sprint content), and source feature (so the same translator handled the same product area consistently). This took about three weeks of engineering work, mostly from our integration engineers working alongside the client's platform team.
We rebuilt the QA layer to catch SaaS-specific issues automatically. Character limit checks against actual UI element constraints (the client gave us their design tokens, so we could check a button label against the actual button width). Placeholder validation. Plural rule validation. Anything that failed automated QA went to the reviewer with a flag explaining what failed. Anything that passed went through. This reduced reviewer load by about 40% and caught issues that human reviewers were missing.
We consolidated translation memory. This was unglamorous work, three weeks of TM cleanup with senior linguists going through 200,000+ existing translation pairs, resolving conflicts, standardizing terminology. By the end, TM leverage went from 35% to 62%, which is a direct cost saving on every subsequent sprint.
The number that mattered most wasn't TAT
Everyone talks about turnaround time. The 5-day to 18-hour improvement was good. But the metric that actually changed how the client operated was sprint adherence.
Before: about 83% of sprints shipped with full localization. The remaining 17% either had English fallback in production for a few days, or got delayed at release.
After: 99.7%. Two missed sprints in nine months, both due to internal client-side issues (a delayed string freeze and one production incident), neither localization-related.
Sprint adherence is the metric that connects localization to product velocity. It's the metric a Head of Globalization can take to their CPO and have a conversation about. TAT is a localization team's metric. Sprint adherence is a company metric.
What I'd do differently
Two things.
First, we underinvested in change management at the start. We spent the first month focused on technical integration and didn't spend enough time on how the client's internal team would adapt to the new workflow. About six weeks in, we realized two of the client's PMs were still manually exporting content because they didn't fully trust the automated routing. We had to backtrack and do proper onboarding sessions. If I were starting over, I'd build the technical pipeline and the human workflow change in parallel from day one.
Second, we didn't push hard enough on TM cleanup early. We treated it as a secondary workstream because we wanted to show TAT improvements fast. In retrospect, the TM cleanup was the work that compounded over time. Three months of cleanup is paying off every sprint now. We could have started it on day one.
Closing thought
The SaaS localization market is in an awkward middle right now. The tier-1 LSPs are still operating on a project-based model that wasn't built for continuous deployment. The pure tech solutions (MT engines, AI translation tools) handle the throughput but not the quality. The companies that win the next decade of SaaS localization are the ones who can do both, pipeline engineering and linguistic quality, in the same shop.
We're trying to be one of those companies. The 25-language continuous pipeline work is part of how we're getting there.
If you're running localization at a SaaS company and the workflow is starting to break, or you're trying to evaluate whether to consolidate vendors, I'm happy to talk through what we've seen. The full case study including metrics breakdown is on our case studies page.
Tags
More Articles
Explore more from our blog
The rare-language problem that the localization industry pretends doesn't exist
A tier-1 global agency came to us last year after exhausting their network on four languages out of eighteen. Sylheti, Rohingya, Khasi, Mizo. The story of how that project went says a lot about a gap in our industry that most agencies don't want to talk about openly.

How we localized an AI product into 40 languages in 6 weeks
A conversational AI company came to us last quarter with a hard deadline: 40 languages in 8 weeks. Their incumbent agency quoted 14. We delivered in 6, including 12 languages the tier-1 LSP had declined to touch. Here's what we learned about localizing AI products that translation work doesn't teach you.
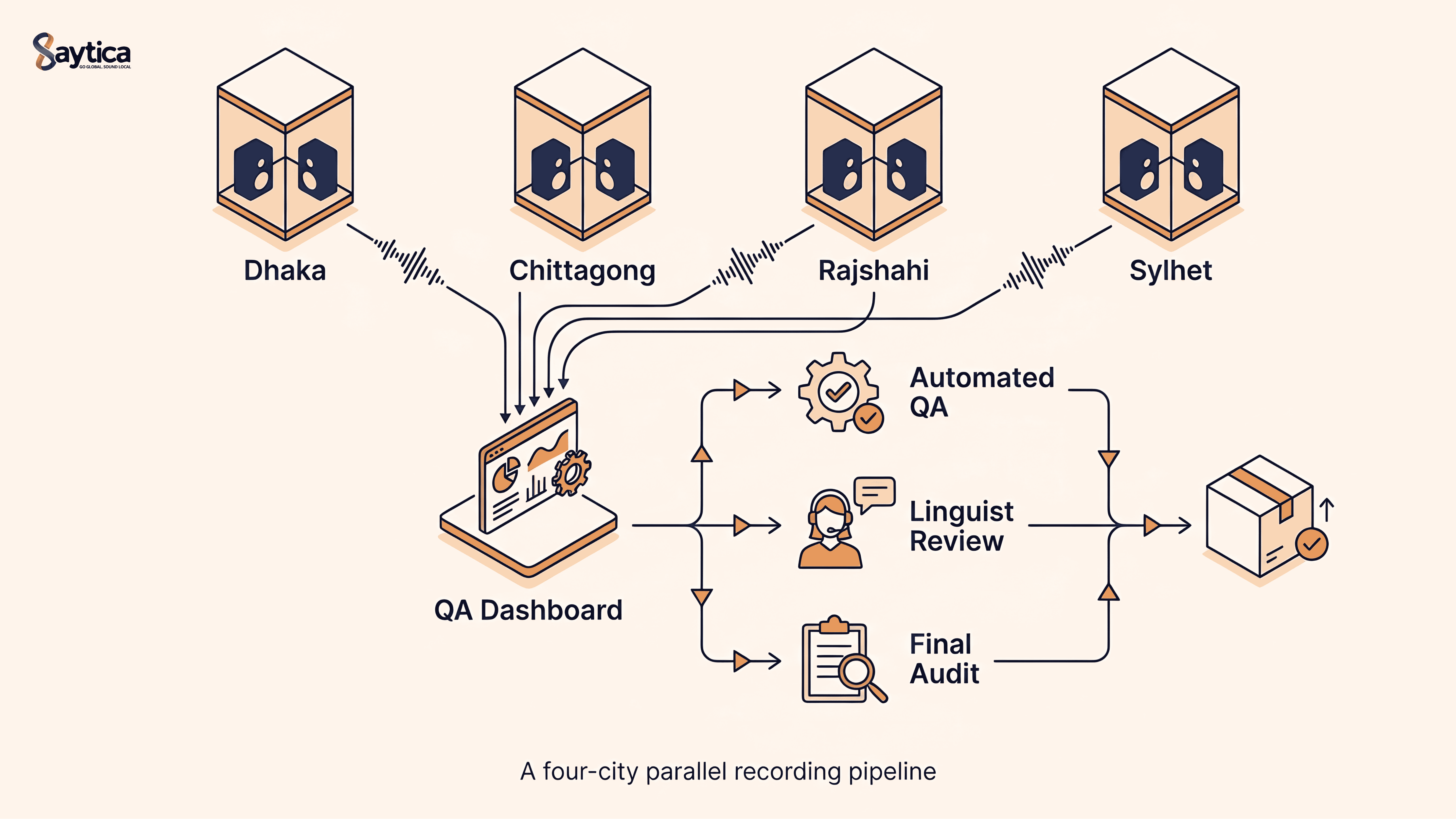
How We Collected 500 Hours of Bangla Duplex Conversational Audio in 6 Weeks — 32% Cheaper, 25% Faster
A global AI lab needed 500 hours of dual-channel Bangla conversational speech for ASR fine-tuning in 8 weeks. We delivered in 6 — at 32% below benchmark cost. Here's exactly how, end to end: speaker recruitment, parallel multi-city recording, three-layer QA, and the operational decisions behind the gains.

The 2025 Localization Playbook: TEP vs MTPE—When to Use Which
Choose the right workflow in 2025. This playbook shows when to use TEP (human translation + edit + proof) and when MTPE makes sense—plus a decision matrix, quality bars, a pilot plan, and risk controls.

Subtitles That Don’t Feel “Machine”: Read-Speed, SDH & Platform Specs
Why some captions feel robotic—and how to fix them fast. A practical guide to read-speed, SDH vs. standard subtitles, on-screen text, and a simple QC checklist you can run before publish.
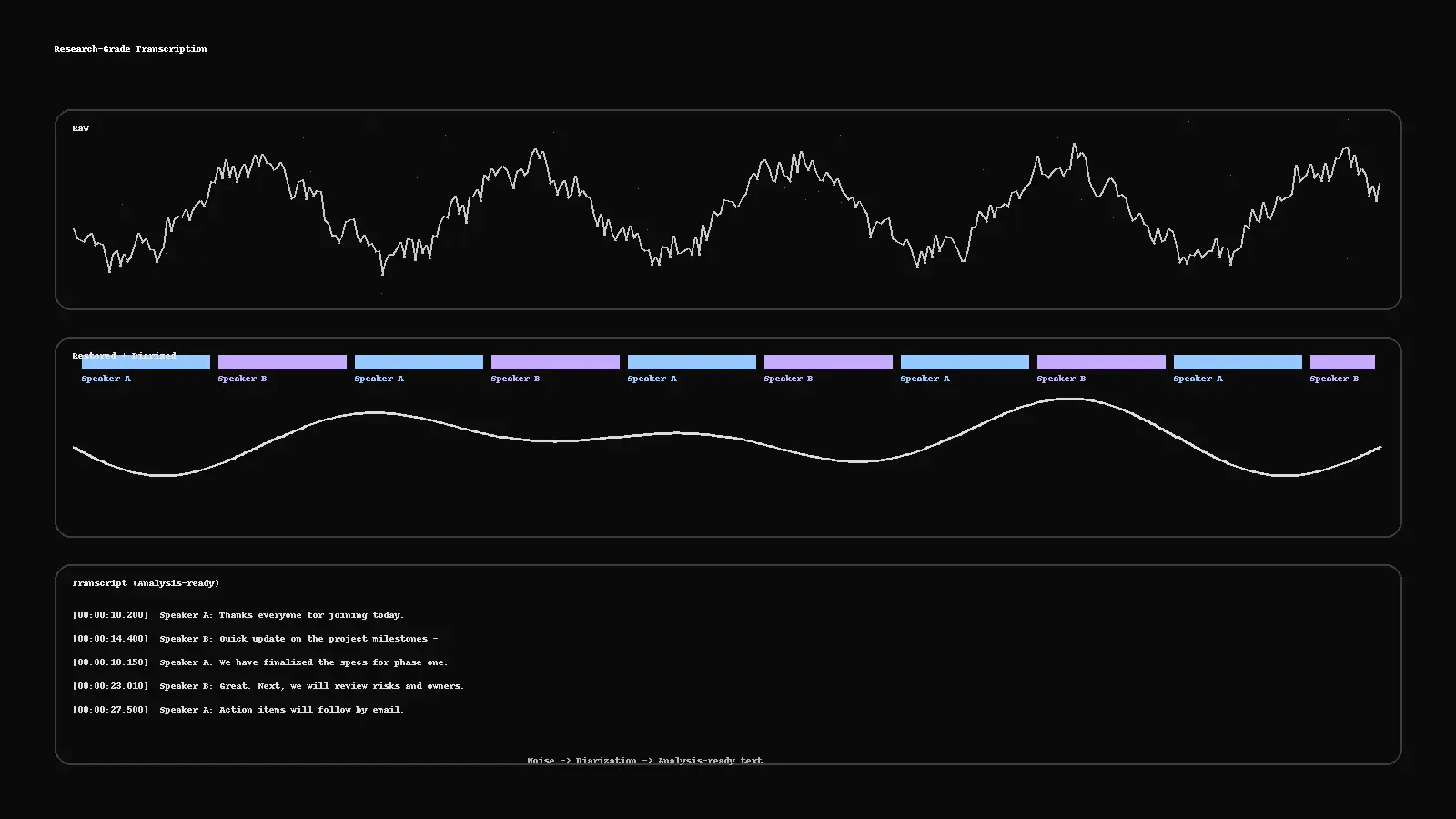
Research-Grade Transcription: From Noisy Audio to Analysis-Ready Text
Turn messy recordings into clean, analysis-ready text. This guide shows a practical pipeline—restoration, diarization, human QC, PII redaction, and deliverables (RTTM, ELAN, TextGrid, SRT)—plus a two-minute checklist to run before publishing.