How We Collected 500 Hours of Bangla Duplex Conversational Audio in 6 Weeks — 32% Cheaper, 25% Faster
A global AI lab needed 500 hours of dual-channel Bangla conversational speech for ASR fine-tuning in 8 weeks. We delivered in 6 — at 32% below benchmark cost. Here's exactly how, end to end: speaker recruitment, parallel multi-city recording, three-layer QA, and the operational decisions behind the gains.
TL;DR — A global AI lab needed 500 hours of high-quality, two-channel Bangla conversational speech for an ASR fine-tuning project. The standard industry timeline for this volume is 8 weeks. We delivered in 6, at a unit cost 32% below the budget our client had benchmarked against three other vendors. Here is exactly how we did it — speaker recruitment, recording setup, QA layers, and the operational decisions that drove the cost and speed gains.
The Brief
The client came to us with a clear specification:
Volume: 500 hours of finished, QA-passed audio
Format: Two-channel duplex (separate channels per speaker)
Speech type: Spontaneous conversational, open-domain
Language: Bangla (Bangladesh variant), with regional diversity
Speakers: 400+ unique speakers; balanced gender and age
Audio quality: SNR > 20 dB, no clipping, 16 kHz / 16-bit minimum
Deliverables: Raw WAV + metadata + speaker demographics + light transcription sample
Timeline: 8 weeks (industry-standard)
The intended use was acoustic model fine-tuning for a multilingual ASR system that already performed well on read speech but struggled on natural turn-taking, overlaps, and disfluencies — exactly the things duplex conversational data captures.
Why This Brief Is Harder Than It Looks
Three things make a 500-hour Bangla duplex collection difficult:
Duplex separation is non-trivial. Most "conversational" datasets in the market are mono mixed-channel. True dual-channel recording requires controlled environments and dedicated capture hardware for each speaker.
Spontaneity vs. control. Read scripts are easy to source. Natural conversations are not — and yet the audio quality must remain studio-grade.
Bangla is a multi-dialect language. A dataset that only captures Dhaka-region speech will not generalize. Regional balance must be planned upfront, not discovered at QA.
Most vendors handle this by routing through subcontractors and accepting a 7–9 week timeline. We took a different approach.
Our Approach: Three Operational Decisions That Changed the Math
1. Pre-Vetted Speaker Pool (Eliminated 60% of Recruitment Time)
The single biggest bottleneck in voice data projects is speaker recruitment. Industry standard is 2–3 weeks just to recruit, screen, and onboard 400+ speakers.
We started with a pre-vetted contributor pool of 2,800+ Bangla speakers maintained inside our annotator network. Each speaker already had:
Verified ID and consent records
Demographic tags (region, age band, gender, education level, occupation)
Audio sample from a prior screening session (so we knew their voice quality and dialect)
Signed master agreement covering IP transfer, recording rights, and data privacy
When the brief landed, our project ops team filtered the pool by demographic targets and sent recording slot invites within 36 hours of kickoff. Recruitment that normally takes 14–18 days was effectively done in 3.
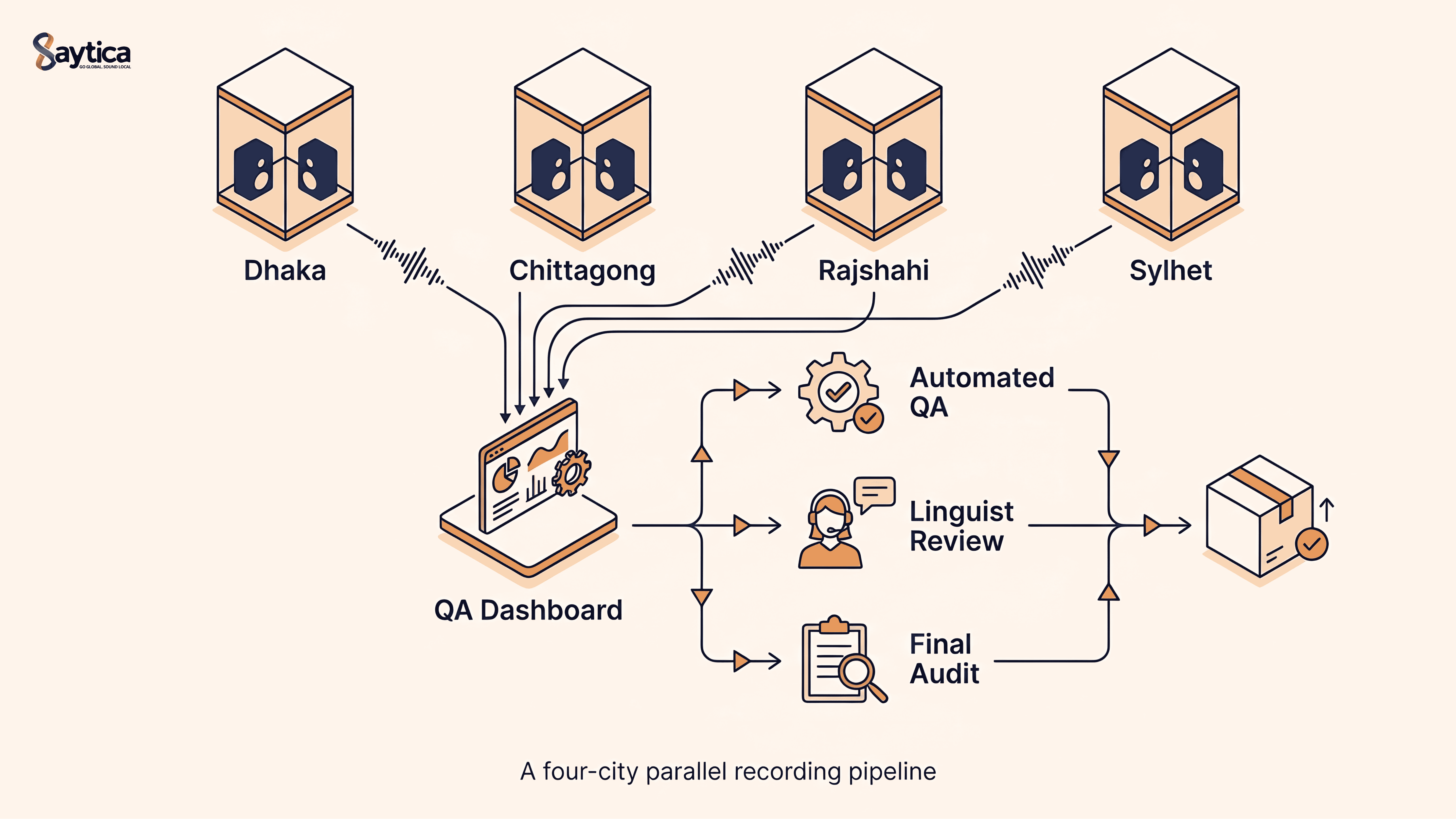
2. Parallel Multi-City Recording (Cut Production Time by ~30%)
We ran recording sessions in four cities simultaneously — Dhaka, Chittagong, Rajshahi, and Sylhet. Each city ran 2–3 booth-equipped recording rooms operated by trained session leads. Speakers were paired in advance based on:
Familiarity (known acquaintances produce more natural turn-taking than strangers)
Age proximity (within ~10 years for register consistency)
Topic compatibility (matched to one of 18 conversation prompts)
Each pair recorded a 45-minute session, with the first 5 minutes treated as warm-up and excluded. Net usable yield averaged 38 minutes per session. To hit 500 hours, we ran roughly 790 sessions over 28 working days — about 28 sessions per day across all locations.
Recording hardware was identical at every site:
Two cardioid condenser mics (one per speaker), routed to separate channels
Acoustic-treated booths with measured RT60 < 0.3s
Calibrated gain levels checked at the start of each session
Live waveform monitoring by the session lead to catch clipping or dropout immediately
3. Same-Timezone, Same-Day QA (Eliminated 5–7 Days of Handoff Lag)
Most international AI data projects lose 5–10 days to overnight handoffs — recording happens in one timezone, QA in another, fixes go back, and so on. Because our entire pipeline runs in Bangladesh, a session recorded at 11 AM was QA-passed or flagged for re-record by 6 PM the same day.
Our QA pipeline ran three layers in parallel:
L1 — Automated checks
What it checks: SNR, clipping, channel balance, silence gaps
Method: Custom Python pipeline run on every file
Pass criteria: SNR > 20 dB, < 0.1% clipped samples
L2 — Linguist spot-check
What it checks: Bangla naturalness, dialect tagging, content appropriateness
Method: Trained QA linguist reviews 20% sample per session
Pass criteria: Inter-annotator agreement > 0.85
L3 — Client-spec audit
What it checks: Demographic balance, topic coverage, metadata completeness
Method: Senior QA lead weekly batch review
Pass criteria: 100% metadata fields populated
Sessions that failed at any layer were re-recorded within 48 hours using a backup speaker pair from the standby pool we kept reserved each week.
Where the 32% Cost Reduction Came From
Cost savings did not come from cutting corners. They came from removing layers that don't add quality:
No subcontracting markup. Many global vendors quote South Asian data collection at rates that include a 25–40% subcontractor handoff margin. Our linguists, session leads, and QA team are all in-house.
In-house recording infrastructure. Owning our booth setups (rather than renting commercial studios per session) reduces variable cost per hour by roughly 35%.
Bangladesh operational base. Skilled audio engineers, linguists, and project managers in Bangladesh deliver enterprise-grade work at a cost base 40–55% below US/EU equivalents — without the quality compromise often associated with offshore work.
Reusable speaker pool amortization. Every speaker we pre-vet is a one-time recruitment cost amortized across multiple projects. New brief, same pool, near-zero recruitment overhead.
The client benchmarked our quote against three other vendors (one US, one Indian, one European). Our final per-hour cost came in 32% below the median of the three competing quotes, with no quality concessions in the SOW.
Where the 25% Time Reduction Came From
The 6-week timeline (vs. 8-week industry standard) broke down like this:
Industry standard breakdown (~56 days total):
Recruitment & onboarding: 14–18 days
Recording (production): 28–35 days
QA & rework: 7–10 days
Final packaging & delivery: 3–5 days
Saytica breakdown (~42 days total):
Recruitment & onboarding: 3 days
Recording (production): 25 days
QA & rework: Same-day rolling
Final packaging & delivery: 3 days
The two biggest gains: pre-vetted pool (saving ~12 days at the front) and same-timezone rolling QA (saving ~5 days at the back). Recording itself was only marginally faster — that part is constrained by physics and speaker availability, not workflow.
Final Quality Outcomes
What was delivered, measured against the SOW:
507.4 hours of QA-passed audio (1.5% buffer over target)
428 unique speakers across Dhaka, Chittagong, Sylhet, Rajshahi, Khulna, Barisal, and Rangpur regions
Gender split: 51% female / 49% male
Age distribution: 18–25 (28%), 26–40 (44%), 41–60 (24%), 60+ (4%)
Mean SNR: 26.4 dB; clipping rate < 0.05%
Inter-annotator agreement on naturalness/quality QA: 0.91
Zero re-delivery requests post-handover
The client's downstream ASR fine-tuning showed measurable WER improvement on conversational benchmarks within their first evaluation cycle. (Specifics confidential under NDA.)
Lessons We Took Forward
A few things this project crystallized for our delivery model:
Speaker pool is the moat. Vendors that recruit fresh for every project will always lose on speed. Maintaining a permanent, demographically tagged contributor network is the single highest-leverage investment in this business.
Same-timezone delivery is underrated. "Follow-the-sun" workflows sound good on slides. In practice, they add 20–30% to project timelines because every handoff is a context loss.
Quality and cost are not on a tradeoff curve when you remove middlemen. The cost savings here came from operational structure, not from cheaper labor or weaker QA.
Regional dialect balance must be designed in. Treating Bangla as a monolith — or letting recruitment happen in whichever city is convenient — produces datasets that look fine on paper and fail in production.
Working With Saytica
If you're building speech systems for Bangla, Hindi, Urdu, or other South Asian languages — and the standard vendor quote feels both too expensive and too slow — that gap is usually structural, not inevitable.
We run similar collections for ASR, TTS, voice biometrics, and conversational AI training across 230+ languages. Briefs in the 200–2,000 hour range are our operational sweet spot. Get in touch at www.saytica.com to discuss your data spec.
Tags
More Articles
Explore more from our blog
The rare-language problem that the localization industry pretends doesn't exist
A tier-1 global agency came to us last year after exhausting their network on four languages out of eighteen. Sylheti, Rohingya, Khasi, Mizo. The story of how that project went says a lot about a gap in our industry that most agencies don't want to talk about openly.
Why most SaaS localization workflows can't keep up with continuous deployment
A SaaS client came to us with a problem that took me a while to fully understand. They were shipping product faster than their localization workflow could move. Three vendors, 25 languages, 5-day turnaround, and roughly 1 in 6 sprints missing translations at release. Here is what we found when we rebuilt their pipeline.

How we localized an AI product into 40 languages in 6 weeks
A conversational AI company came to us last quarter with a hard deadline: 40 languages in 8 weeks. Their incumbent agency quoted 14. We delivered in 6, including 12 languages the tier-1 LSP had declined to touch. Here's what we learned about localizing AI products that translation work doesn't teach you.

The 2025 Localization Playbook: TEP vs MTPE—When to Use Which
Choose the right workflow in 2025. This playbook shows when to use TEP (human translation + edit + proof) and when MTPE makes sense—plus a decision matrix, quality bars, a pilot plan, and risk controls.

Subtitles That Don’t Feel “Machine”: Read-Speed, SDH & Platform Specs
Why some captions feel robotic—and how to fix them fast. A practical guide to read-speed, SDH vs. standard subtitles, on-screen text, and a simple QC checklist you can run before publish.
Research-Grade Transcription: From Noisy Audio to Analysis-Ready Text
Turn messy recordings into clean, analysis-ready text. This guide shows a practical pipeline—restoration, diarization, human QC, PII redaction, and deliverables (RTTM, ELAN, TextGrid, SRT)—plus a two-minute checklist to run before publishing.